👋 Hey there,
Sukhmander Singh
🚀 Senior IT Engineer | IAM / MDM / Collaboration Stack Automation
📍 San Francisco, United States
💡 Built and operated IAM/SSO (Okta), MDM (Jamf/Intune), and collaboration stacks (Google Workspace / M365) with automation (bash/Python, APIs) and vendor/SLA ownership. Enforce least-privilege, standardize onboarding/offboarding and asset lifecycle, drive audit readiness, and use metrics + post-incident RCAs to continuously improve service quality.
✨ Highlights
Automation-first approach across Okta, Jamf, Intune, and collaboration suites to reduce toil and speed delivery
Policy-as-code access mapping, self-service access requests, and auditable approvals for least-privilege IAM
Designing AI agents that answer questions and execute safe actions to reduce Tier-1/Tier-2 workload and MTTR
🛠️ Skills
A sample of the capabilities I bring to every engagement.
🧰 Tools & Products
Crafted accelerators ready for teams or fellow builders; to view the full list go to:
tools.sukhi.is-a.dev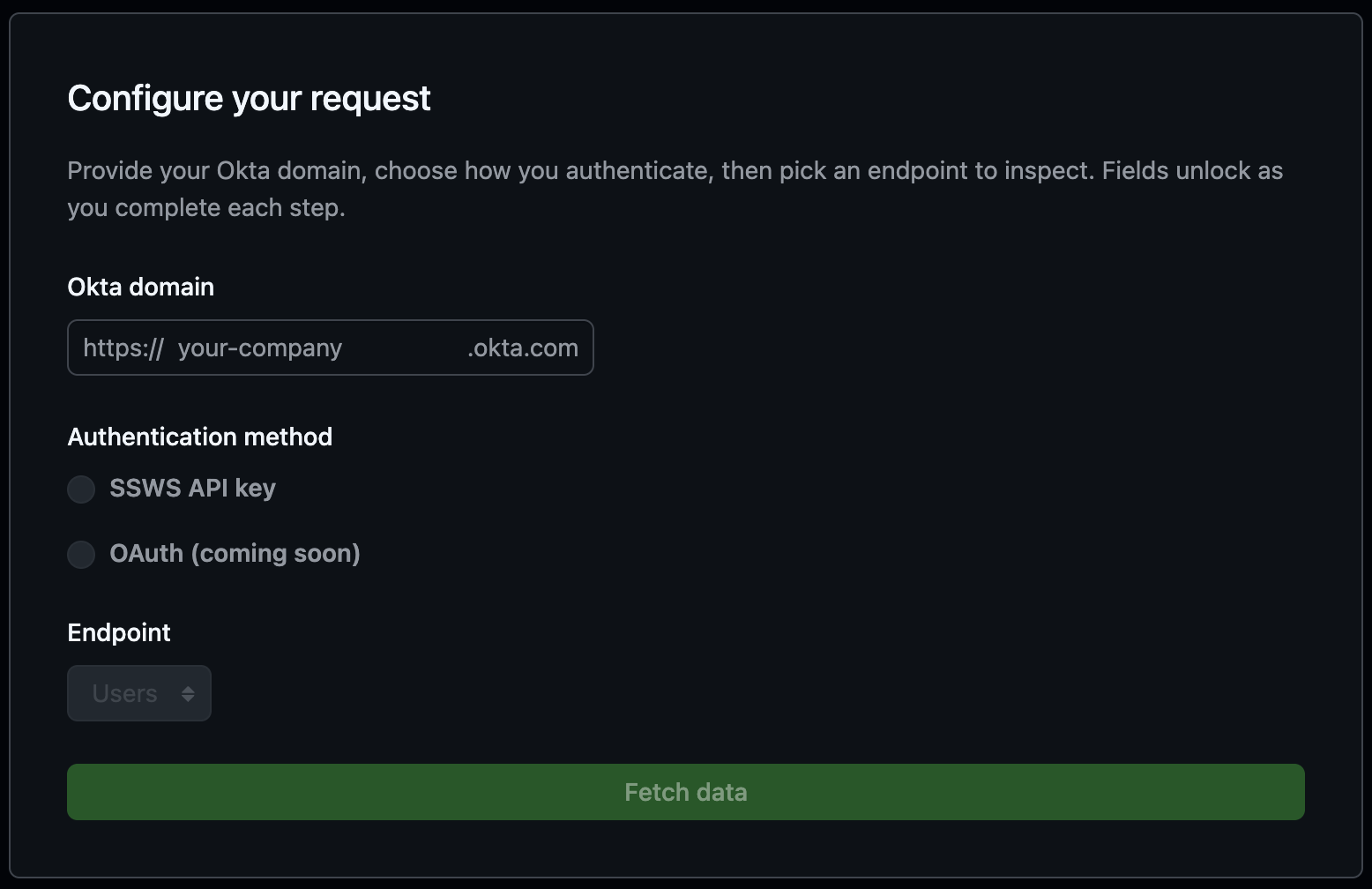
Okta Data Fetcher
Okta Data Fetcher
A modern web application that allows you to inspect Okta REST endpoints, flatten nested payloads, and export curated CSVs without leaving the browser.
🤝 Let us collaborate
Share a little context about the work you have in mind and I will follow up promptly.
Let me know how we can create impact together.
📍 Based in San Francisco, United States